Kappa
“Great things are not done by impulse, but by a series of small things brought together.”
Hack The Box
Logistic Regression
Despite its name, logistic regression is a supervised learning algorithm primarily used for classification, not regression. It predicts a categorical target variable with two possible outcomes (binary classification). These outcomes are typically represented as binary values (e.g., 0 or 1, true or false, yes or no).
{kind=link}
For example, logistic regression can predict whether an email is spam or not or whether a customer will click on an ad. The algorithm models the probability of the target variable belonging to a particular class using a logistic function, which maps the input features to a value between 0 and 1.
What is Classification?
Before we delve deeper into logistic regression, let's clarify what classification means in machine learning. Classification is a type of supervised learning that aims to assign data points to specific categories or classes. Unlike regression, which predicts a continuous value, classification predicts a discrete label.
Examples of classification problems include:
- Identifying fraudulent transactions (fraudulent or not fraudulent)
- Classifying images of animals (cat, dog, bird, etc.)
- Diagnosing diseases based on patient symptoms (disease present or not present)
In all these cases, the output we're trying to predict is a category or class label.
How Logistic Regression Works
Unlike linear regression, which outputs a continuous value, logistic regression outputs a probability score between 0 and 1. This score represents the likelihood of the input belonging to the positive class (typically denoted as '1').
It achieves this by employing a sigmoid function, which maps any input value (a linear combination of features) to a value within the 0 to 1 range. This function introduces non-linearity, allowing the model to capture complex relationships between the features and the probability of the outcome.
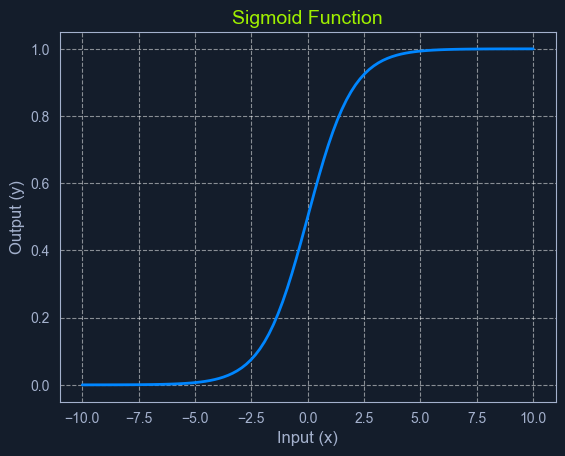
What is a Sigmoid Function?
{kind=link}
The sigmoid function is a mathematical function that takes any input value (ranging from negative to positive infinity) and maps it to an output value between 0 and 1. This makes it particularly useful for modeling probabilities.
The sigmoid function has a characteristic "S" shape, hence its name. It starts with low values for negative inputs, then rapidly increases around zero, and finally plateaus at high values for positive ones. This smooth, gradual transition between 0 and 1 allows it to represent the probability of an event occurring.
In logistic regression, the sigmoid function transforms the linear combination of input features into a probability score. This score represents the likelihood of the input belonging to the positive class.
The Sigmoid Function
The sigmoid function's mathematical representation is:
P(x) = 1 / (1 + e^-z)
Where:
P(x) is the predicted probability.
e is the base of the natural logarithm (approximately 2.718).
z is the linear combination of input features and their weights, similar to the linear regression equation: z = m1x1 + m2x2 + ... + mnxn + c
Spam Detection
Let's say we're building a spam filter using logistic regression. The algorithm would analyze various email features, such as the sender's address, the presence of certain keywords, and the email's content, to calculate a probability score. The email will be classified as spam if the score exceeds a predefined threshold (e.g., 0.8).
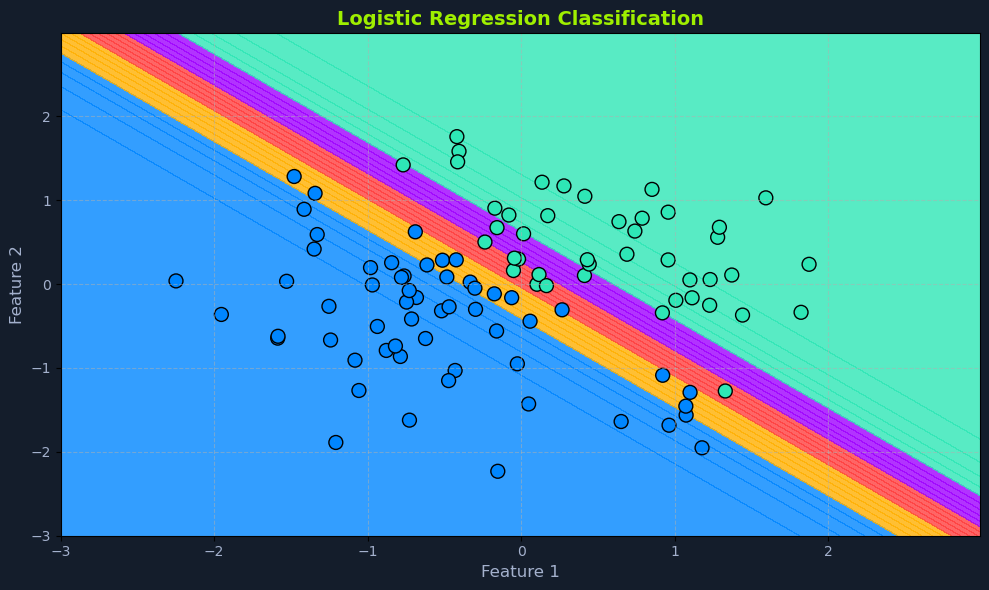
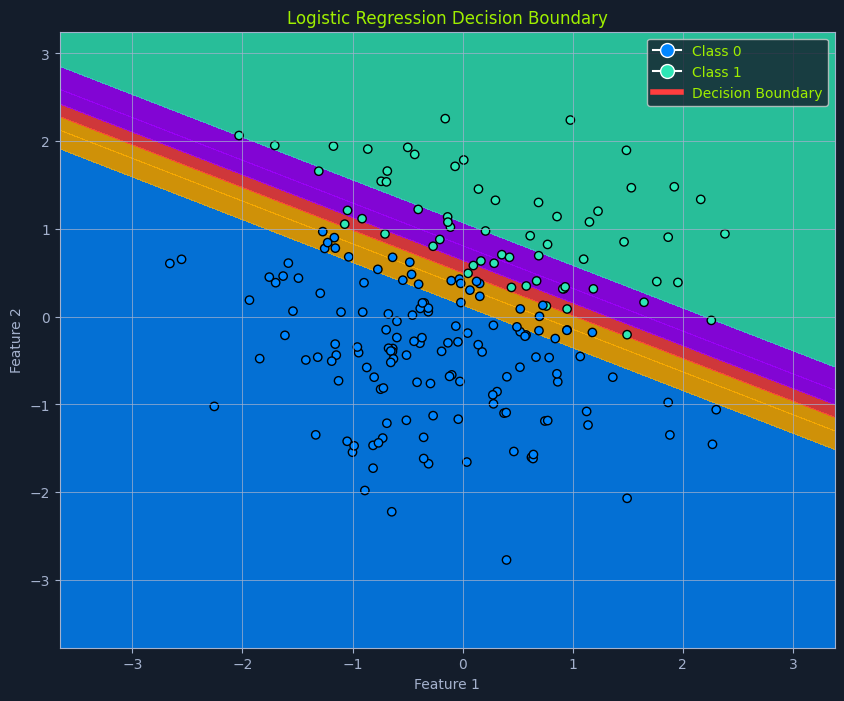
Decision Boundary
A crucial aspect of logistic regression is the decision boundary. In a simplified scenario with two features, imagine a line separating the data points into two classes. This separator is the decision boundary, determined by the model's learned parameters and the chosen threshold probability.
{kind=link}
In higher dimensions with more features, this separator becomes a hyperplane. The decision boundary defines the cutoff point for classifying an instance into one class or another.
Understanding Hyperplanes
In the context of machine learning, a hyperplane is a subspace whose dimension is one less than that of the ambient space. It's a way to visualize a decision boundary in higher dimensions.
{kind=link}
Think of it this way:
- A hyperplane is simply a line in a 2-dimensional space (like a sheet of paper) that divides the space into two regions.
- A hyperplane is a flat plane in a 3-dimensional space (like your room) that divides the space into two halves.
Moving to higher dimensions (with more than three features) makes it difficult to visualize, but the concept remains the same. A hyperplane is a "flat" subspace that divides the higher-dimensional space into two regions.
In logistic regression, the hyperplane is defined by the model's learned parameters (coefficients) and the chosen threshold probability. It acts as the decision boundary, separating data points into classes based on their predicted probabilities.
Threshold Probability
The threshold probability is often set at 0.5 but can be adjusted depending on the specific problem and the desired balance between true and false positives.
- If a given data point's predicted probability P(x) falls above the threshold, the instance is classified as the positive class.
- If P(x) falls below the threshold, it's classified as the negative class.
For example, in spam detection, if the model predicts an email has a 0.8 probability of being spam (and the threshold is 0.5), it's classified as spam. Adjusting the threshold to 0.6 would require a higher probability for the email to be classified as spam.
Data Assumptions
While not as strict as linear regression, logistic regression does have some underlying assumptions about the data:
- Binary Outcome: - The target variable must be categorical, with only two possible outcomes.
- Linearity of Log Odds: - It assumes a linear relationship between the predictor variables and the log-odds of the outcome. Log odds are a transformation of probability, representing the logarithm of the odds ratio (the probability of an event occurring divided by the probability of it not occurring).
- No or Little Multicollinearity: - Ideally, there should be little to no multicollinearity among the predictor variables. Multicollinearity occurs when predictor variables are highly correlated, making it difficult to determine their individual effects on the outcome.
- Large Sample Size: - Logistic regression performs better with larger datasets, allowing for more reliable parameter estimation.
Assessing these assumptions before applying logistic regression helps ensure the model's accuracy and reliability. Techniques like data exploration, visualization, and statistical tests can be used to evaluate these assumptions.